微信关注,了解更多
微信关注,了解更多 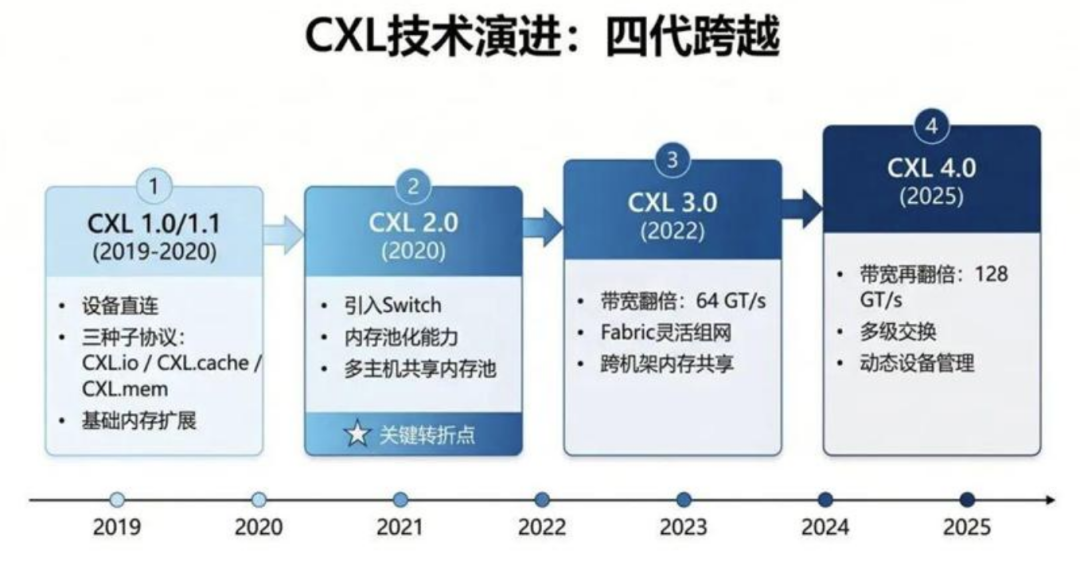
在大模型算力暴涨、智能驾驶迈向中央域控的产业浪潮下,CXL(高速互联总线)已成为破除内存墙、异构算力割裂的核心技术,从云端 AI 数据中心快速下沉至车载计算平台。依托 SmartDV 成熟 CXL 全栈 IP 方案,芯片设计企业大幅缩短研发周期,加速新一代 AI 加速芯片、车载主控 SoC 量产落地,重塑算力硬件底层架构。
长久以来,AI 大模型训练与推理长期受困内存瓶颈:CPU、GPU、NPU 显存相互独立,硬件资源无法共享,单卡内存上限束缚大模型并发部署,GPU 资源利用率常年不足 40%;而智能汽车从分布式 ECU 升级中央计算架构后,多颗算力芯片、多路雷达摄像头数据交互频繁,传统 PCIe 总线带宽不足、延迟偏高,难以满足车规毫秒级决策需求,CXL 技术恰好破解两大行业痛点。凭借 CXL.cache、CXL.io、CXL.mem 三层协议,实现跨芯片缓存一致性与内存池化,单链路最高 64GT/s 传输速率,算力硬件可灵活扩容内存,AI 集群硬件利用率提升至 75% 以上;车载端打通异构芯片数据壁垒,多域算力统一调度,适配车载端大模型本地化运行需求。
作为 CXL 联盟核心成员,SmartDV 布局全栈 CXL 设计 IP 与验证 IP,完整覆盖 CXL1.x/2.0/3.1 全版本协议,向下兼容 PCIe5.0/6.0 规范,可适配 ASIC 与 FPGA 两种芯片开发路径,兼顾数据中心高算力、车载高可靠双场景开发需求。以往自研 CXL 协议架构,工程师需耗费数月调试协议兼容性、搭建验证环境,版本迭代还要同步跟进 CXL 规范更新;搭载成熟商用 IP 后,厂商可直接调用标准化控制器内核,省去底层协议开发,芯片研发周期缩短 40%,同时配套完备 UVM 验证 IP,规避协议兼容 BUG,大幅降低流片失败风险。
落地场景上,CXL+IP 双组合开启两大黄金赛道。AI 领域,服务器芯片、AI 加速卡通过 CXL IP 快速集成内存扩展接口,搭建池化内存架构,千亿参数大模型训练节点数量精简,有效削减 IDC 建设与用电成本;车载领域,域控 SoC 嵌入车规级 CXL IP,实现座舱、智驾算力硬件解耦,硬件按需灵活扩容,车企不用反复迭代整车芯片方案,加速高阶自动驾驶车型量产落地。
当下 CXL 产业进入规模化落地元年,海内外算力芯片、车载半导体厂商纷纷布局相关产品。SmartDV 全栈 CXL IP 凭借兼容性与落地成熟度,成为产业链国产化关键一环。随着 CXL4.0 标准逐步落地,高速互联 IP 将进一步下沉至边缘终端,未来无论是云端超算还是车载终端,CXL 都将成为算力芯片标配,撬动千亿级半导体硬件增量市场。
未经允许不得转载:物联网的那些事 - Totiot » CXL 打通算力新基建!全栈 IP 落地,加速 AI 与车载芯片国产化迭代